Prompt injection and LLM Security
Deep Dive into the current state of the art of LLM risk and security
WPP CTO Office
1 presentation · 77 resources
Workshop slides and training materials
Deep Dive into the current state of the art of LLM risk and security
17 resources in ⭐ Recommended Reading
CSA releases an addendum to support system owners in securing agentic AI systems for public consultation.

Really good research on practical attacks against LLM agents. “Invitation Is All You Need! Promptware Attacks Against LLM-Powered Assistants in Production Are Practical and Dangerous” Abstract: The growing integration of LLMs into applications has introduced new security risks, notably known as Promptware—maliciously engineered prompts designed to manipulate LLMs to compromise the CIA triad of these applications. While prior research warned about a potential shift in the threat landscape for LLM-powered applications, the risk posed by Promptware is frequently perceived as low. In this paper, we investigate the risk Promptware poses to users of Gemini-powered assistants (web application, mobile application, and Google Assistant). We propose a novel Threat Analysis and Risk Assessment (TARA) framework to assess Promptware risks for end users. Our analysis focuses on a new variant of Promptware called Targeted Promptware Attacks, which leverage indirect prompt injection via common user interactions such as emails, calendar invitations, and shared documents. We demonstrate 14 attack scenarios applied against Gemini-powered assistants across five identified threat classes: Short-term Context Poisoning, Permanent Memory Poisoning, Tool Misuse, Automatic Agent Invocation, and Automatic App Invocation. These attacks highlight both digital and physical consequences, including spamming, phishing, disinformation campaigns, data exfiltration, unapproved user video streaming, and control of home automation devices. We reveal Promptware’s potential for on-device lateral movement, escaping the boundaries of the LLM-powered application, to trigger malicious actions using a device’s applications. Our TARA reveals that 73% of the analyzed threats pose High-Critical risk to end users. We discuss mitigations and reassess the risk (in response to deployed mitigations) and show that the risk could be reduced significantly to Very Low-Medium. We disclosed our findings to Google, which deployed dedicated mitigations…

James Mickens, Harvard UniversityQ: Why Do Keynote Speakers Keep Suggesting That Improving Security Is Possible?A: Because Keynote Speakers Make Bad Life Dec…

Go beyond model scores and blind fuzzing, test your agentic systems against real-world risks.

The starting point for information about the AI Incident Database
PDF file: NI_AI_2025.pdf

Large language models perform near-Bayesian inference yet violate permutation invariance on exchangeable data. We resolve this by showing transformers minimize expected conditional description length (cross-entropy) over orderings, $\mathbb{E}_π[\ell(Y \mid Γ_π(X))]$, which admits a Kolmogorov-complexity interpretation up to additive constants, rather than the permutation-invariant description length $\ell(Y \mid X)$. This makes them Bayesian in expectation, not in realization. We derive (i) a Quantified Martingale Violation bound showing order-induced deviations scale as $O(\log n)$ with constants; (ii) the Expectation-level Decompression Law linking information budgets to reliability for Bernoulli predicates; and (iii) deployable planners (B2T/RoH/ISR) for answer/abstain decisions. Empirically, permutation dispersion follows $a+b\ln n$ (Qwen2-7B $b \approx 0.377$, Llama-3.1-8B $b \approx 0.147$); permutation mixtures improve ground-truth likelihood/accuracy; and randomized dose-response shows hallucinations drop by $\sim 0.13$ per additional nat. A pre-specified audit with a fixed ISR=1.0 achieves near-0\% hallucinations via calibrated refusal at 24\% abstention. The framework turns hallucinations into predictable compression failures and enables principled information budgeting.
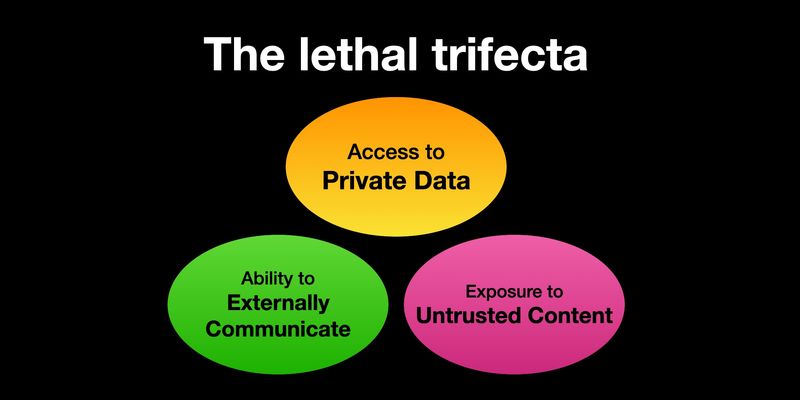
If you are a user of LLM systems that use tools (you can call them “AI agents” if you like) it is critically important that you understand the risk of …
Prompt injection attacks, where malicious input is designed to manipulate AI systems into ignoring their original instructions and following unauthorized commands instead, were first discovered by Preamble, Inc. in May 2022 and responsibly disclosed to OpenAI. Over the last three years, these attacks have continued to pose a critical security threat to LLM-integrated systems. The emergence of agentic AI systems, where LLMs autonomously perform multistep tasks through tools and coordination with other agents, has fundamentally transformed the threat landscape. Modern prompt injection attacks can now combine with traditional cybersecurity exploits to create hybrid threats that systematically evade traditional security controls. This paper presents a comprehensive analysis of Prompt Injection 2.0, examining how prompt injections integrate with Cross-Site Scripting (XSS), Cross-Site Request Forgery (CSRF), and other web security vulnerabilities to bypass traditional security measures. We build upon Preamble’s foundational research and mitigation technologies, evaluating them against contemporary threats, including AI worms, multi-agent infections, and hybrid cyber-AI attacks. Our analysis incorporates recent benchmarks that demonstrate how traditional web application firewalls, XSS filters, and CSRF tokens fail against AI-enhanced attacks. We also present architectural solutions that combine prompt isolation, runtime security, and privilege separation with novel threat detection capabilities.
Contribute to leochlon/hallbayes development by creating an account on GitHub.
Every practical and proposed defense against prompt injection. - tldrsec/prompt-injection-defenses

I gave a talk on Wednesday at the Bay Area AI Security Meetup about prompt injection, the lethal trifecta and the challenges of securing systems that use MCP. It wasn’t …
Autonomous AI agents powered by large language models (LLMs) with structured function-calling interfaces have dramatically expanded capabilities for real-time data retrieval, complex computation, and multi-step orchestration. Yet, the explosive proliferation of plugins, connectors, and inter-agent protocols has outpaced discovery mechanisms and security practices, resulting in brittle integrations vulnerable to diverse threats. In this survey, we introduce the first unified, end-to-end threat model for LLM-agent ecosystems, spanning host-to-tool and agent-to-agent communications, formalize adversary capabilities and attacker objectives, and catalog over thirty attack techniques. Specifically, we organized the threat model into four domains: Input Manipulation (e.g., prompt injections, long-context hijacks, multimodal adversarial inputs), Model Compromise (e.g., prompt- and parameter-level backdoors, composite and encrypted multi-backdoors, poisoning strategies), System and Privacy Attacks (e.g., speculative side-channels, membership inference, retrieval poisoning, social-engineering simulations), and Protocol Vulnerabilities (e.g., exploits in Model Context Protocol (MCP), Agent Communication Protocol (ACP), Agent Network Protocol (ANP), and Agent-to-Agent (A2A) protocol). For each category, we review representative scenarios, assess real-world feasibility, and evaluate existing defenses. Building on our threat taxonomy, we identify key open challenges and future research directions, such as securing MCP deployments through dynamic trust management and cryptographic provenance tracking; designing and hardening Agentic Web Interfaces; and achieving resilience in multi-agent and federated environments. Our work provides a comprehensive reference to guide the design of robust defense mechanisms and establish best practices for resilient LLM-agent workflows.

Recently, reporters from People’s Daily (PD) engaged in face-to-face communication with Huawei CEO Ren Zhengfei (Ren) on various hot topics of public interest at the company’s headquarters in Shenzhen, South China’s Guangdong Province. From this interaction, we genuinely felt the confidence of an entrepreneur who “unswervingly manages own affairs well.”

How to exploit US market narrative and AI hype with a bunch of H800 cards, some nerdy science and Open Source.

CIOs are so desperate to stop generative AI hallucinations they’ll believe anything. Unfortunately, Agentic RAG isn’t new and its abilities are exaggerated.
If you want to make a really big AI model — the kind that can generate images or do your homework, or build this website, or fake a moon landing — you start by finding a really big training set.